일단 전체적인 날짜에 pickup_datetime을 시각 해본 결과 시각화의 대참사가 일어났다.
qs = """
SELECT
pickup,
count(*) as time
FROM
(SELECT
split(pickup_datetime, " ")[0] as pickup
FROM
trips
)
GROUP BY
pickup
ORDER BY
pickup
"""
time_data = spark.sql(qs).toPandas()
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(100, 9))
sns.barplot(x="pickup", y="time", data=time_data)
plt.xticks(rotation=45)
plt.title("NYC Texi 2020-01-01 ~ 2021-01-01")
plt.show()
너무.. 길어.....
근데!!!!!!!!!
보이는가?
보이는가? 갑자기 가파르게 곡선을 그리며 택시 유동성 대참사가 일어난 부분이 보이는가?
몹시 흥미로웠다. 해당 날짜를 알기 위해 저 기다란 시각화를 각 월별로 끊어서 3x4 시각화를 진행했다..
from typing importList
directory: str = [f"{os.getcwd()}/data/{i}"for i in os.listdir(f"{os.getcwd()}/data")][2]
filename: List[str] = [f"{directory}/{data}"for data in os.listdir(directory)]
filename.sort()
defyear_read_data() -> List:return [spark.read.parquet(f"file:///{data}") for data in filename]
defyear_data_topandas_transform(table_name: str, qs: str) -> List[SparkSession]:
t_pickup_dat = []
for data in year_read_data():
data.createOrReplaceTempView(table_name)
td = spark.sql(qs).toPandas()
t_pickup_dat.append(td)
return t_pickup_dat
defbarplot_3to4_visualization(x: str, y:str, data: List,
n_rows: int = 3, n_cols: int = 4) -> None:
fig, ax = plt.subplots(n_rows, n_cols, figsize=(30, 10))
plt.subplots_adjust(wspace = 0.4, hspace = 0.4)
fig.set_size_inches((80, 20))
for i, axi inenumerate(ax.flat):
sns.barplot(x=x, y=y, data=data[i], ax=axi)
axi.set_title(f'taxi 2020 --> date {i+1}')
axi.set_xticklabels(axi.get_xticklabels(), rotation=30)
# 데이터 플롯 출력
plt.show()
qs_2020 = """
SELECT
date,
count(*) as pickup
FROM
(SELECT
split(pickup_datetime, " ")[0] as date
FROM
trips
)
GROUP BY
date
ORDER BY
date
"""
data2020_all = year_data_topandas_transform(table_name="trips", qs=qs_2020)
barplot_3to4_visualization(x="date", y="pickup", data=data2020_all)
Path lib 쓸려고 했지만 나의 목표는 root directory에서 파일을 찾는 것이므로 굳이 쓸 필요는 없었다
경로 custom을 하려면 pathlib 가 좋지만 단순하게 루트에서 파일만 찾는 것이기에 과도한 거 같아 os lib를 사용하였다..
listdir를 사용해서 해당 데이터의 순서를 for문을 이용 list compresension을 이용하여 2020년 데이터를 가져왔다.
코드의 궁금한점이 있으면 질문 환영합니다 태클도 환영합니다 레알 환영 저는 코드를 발전해나가고 싶어요..
집단 지성을 경험하고싶습니다..
아무튼..!!
이렇게 해서 시각화를 한 결과 다음과 같은 결과가 나왔다.
여기에서 3월 그래프를 잘보자유동량이 대참사난걸 확인할 수 있다..!!
선 그래프로 확인해 보자..
2020년 3월
정확하게 일치한다.. 정리를 하면 월평균 80만 대의 택시 유동량이 3월 13일 부터 하강 곡선이 있고
그 이후로 보터 월 유동량이 하락한 걸 볼 수 있다..
2월 ~ 3월 4월
4월부터 16만 대 3월 대비 3.5배의 유동량이 감소했다는 것이다... 바로 코로롱으로 인한 뉴욕 shutdown이 일어난 시점이다..
1월 ~ 4월까지의 데이터를 쭉 나열해서 보면..
1월 ~ 4월 그래프
이러한 그래프를 확인할 수 있었다.
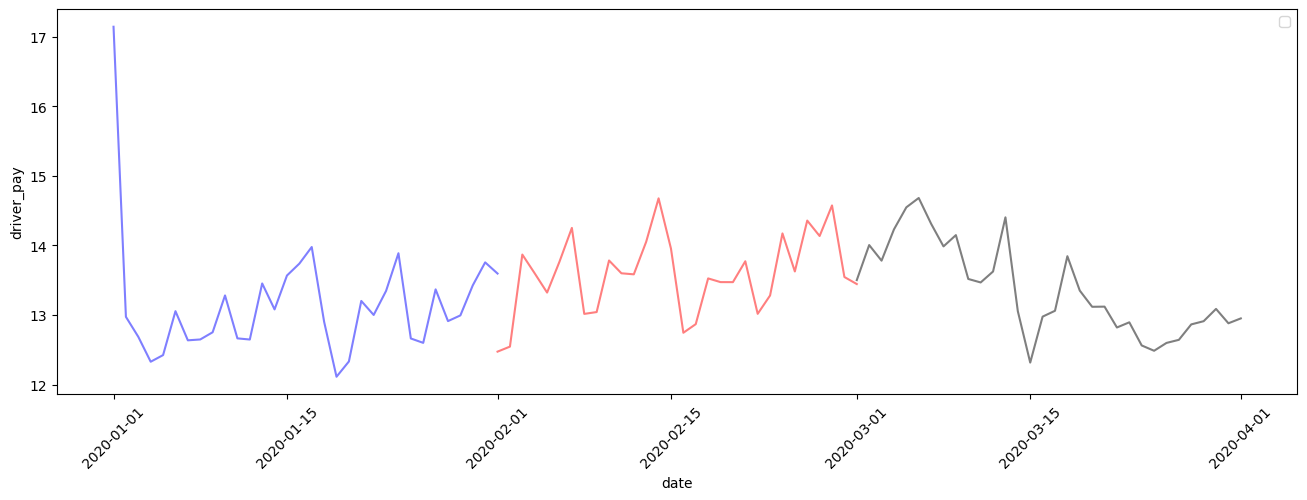
그러면 ... 3월 에 driver pay 는 어떠한지를 확인하였다.. 유동량이 엄청나게 떨어졋을터 기사분들 pay도 떨어졌을지 않을까 생각해봤다
일단 데이터의 평균값부터 살펴보기로 했다.
ㅇㅋㅋㅋㅋㅋㅋ
전처리 진행하자...!!
qs = """
SELECT
TO_DATE(pickup_datetime) as pickup_datetime,
trip_miles as trip_miles,
trip_time as trip_time,
base_passenger_fare,
tips,
driver_pay
FROM
trips
WHERE
base_passenger_fare BETWEEN 1 AND 30
AND trip_miles BETWEEN 1 AND 47
AND trip_time > 0
AND tips BETWEEN 2 AND 100
AND driver_pay BETWEEN 5 AND 500
"""
data = spark.sql(qs)
data.createOrReplaceTempView("data")
qs = """
SELECT
TO_DATE(pickup_datetime) as date,
AVG(trip_miles) as trip_miles,
CAST(AVG(trip_time) as INTEGER) as trip_time,
CAST(AVG(base_passenger_fare) as INTEGER) as base_passenger_fare,
AVG(tips) as tips,
AVG(driver_pay) as driver_pay,
COUNT(split(pickup_datetime, " ")[0]) as pickup_datetime
FROM
trips
GROUP BY
date
ORDER BY
date
"""
preprocessing_3_to_4 = year_data_topandas_transform(table_name="data", qs=qs)
fig, ax = plt.subplots(figsize=(16, 5))
sns.barplot(x="driver_pay", y="date", data=preprocessing_3_to_4[2], alpha=0.5, color="blue")
plt.xticks(rotation=45)
plt.legend()
plt.show()
sns.lineplot(x="date", y="driver_pay", data=preprocessing_3_to_4[2], alpha=0.5)
plt.xticks(rotation=45)
plt.legend()
plt.show()
전처리를 진행하고 시각화를 하니 역시나 3월 15일 펜데믹이 터지고 나서 유동량 급갑으로 기사분들의 수익이 뚝떨어진걸 확인하였다
3월 driver pay
보이는가? 1월 부터 17달러에서 출발해 급격한 하락 후 3월 1일까지 괜찮는 행보( 13~15)달러의 수입원이 있었으나