
신뢰성은 얼마나 중요할까?
증명되지 않는 시장을 위해 시제품을 개발하는 비용이나 매주 작은 이익률의 서비스를 운영하는 비용을 줄이려
신뢰성을 희생해야 하는 상황이 있다 하지만 이 경우에는 비용을 줄여야 하는 시점을 잘 알고 있어야 한다
이러한 상황은 뭐가 있을까?
- 시장 검증 전 초기단계
- 고비용 구조를 유지하기보다는 빠른 테스트와 피드백 수집을 통해 시장 반응을 확인하는 게 우선
- 제품-시장 적합성 찾기 전
- 제품이 시장에서 명확한 적합성을 찾지 못했을 때 최소한의 기능으로 테스트하는 것이 효과적
- 높은 경쟁압력의 초반 단계
- 빠르게 움직이는 산업시장에서 초기에는 자리선점이 중요하다고 생각
- 자금 소진 위험
- 할 말은 많으나 말하지 않겠음
- MVP 개발 단계
- 이것 또한
확장성
시스템이 현재 안정적으로 동작한다고 해서 미래에도 안정적으로 동작한다는 보장이 없음
- 성능 저하를 유발하는 흔한 이유 중 하나는 부하증가
- 사용자가 늘었거나.. 처리량이 증가했거나..
확장성은 증가한 부하에 대처하는 시스템 능력을 활용하는 데 사용하는 용어지만
시스템에 부여하는 일차원 적인 표식이 아님을 주의하자
확장성은 논한다는 것은
- 시스템이 특정 방식으로 커진다면 이에 대처하는 선택은 무엇인가..?
- 스타트업에서 제공하는 웹서비스가 홍보에 성공하여 사용자 수가 폭발적으로 증가했을 때..
- 시간이 지나면서 시스템이 기능적으로 확장되고 유지보수가 어려워진때
- 기존에 있던 데이터 양이 급격하게 증가해서 파이프라인의 처리량 또는 스토리지가 감당이 안될 때
- 추가 부하를 다루기 위해서 계산 자원을 어떻게 투입할 건가..?
- 수평적 확장, 수직적 확장이 있을 것이다. 클라우드… 오토스케일링.. ㅎㅎ 말은 쉽다..

부하 기술하기
무엇보다 시스템의 현재 부하를 간결하게 기술해야 한다
부하매개변수
- 웹 서버의 초당 요청 수
- 데이터베이스의 읽기 대 쓰기 비율
- 캐시 적중률
평균적인 경우가 중요할 수 있고 소수의 극단적인 경우가 병목의 대상일 수 있다
책에서는 트위터를 통해서 부하분산의 극복점을 말하고 있는데
문제를 재현해 보자


확장성 문제에서의 팬아웃 현상이 일어났다고 했다
- 나는 현재 대규모 애플리케이션을 운영하는 개발자이다 사용자 요청이 들어올 때마다 데이터를 가공하고
- 여러 하위 서비스에서 추가 데이터를 가지고 와야 하는 상황
- 그러나 이 하위 서비스가 증가하면서 작업이 동시에 실행되며
- 시스템에 과부하가 일어나고 있는 상황에서 지연 시간이 길어지기 시작함
- 트위터에서는 간단하게 2가지라고 하였다
- 트윗 작성
- 사용자는 팔로워에게 새로운 메시지를 게시할 수 있다
- 홈 타임라인
- 사용자는 팔로우한 사람이 작성한 트윗을 볼 수 있다 (초당 300K 요청
- 트윗 작성
단순이 초당 1만 2천 건 쓰기 처리를 쉽다고 한다 트위터에서 확장성의 문제는 주로 트윗 양이 아닌 팬아웃 현상이라고 말하였는데
개별 사용자는 많은 사람을 팔로우하고 많은 사람들이 개별 사용자를 팔로우한다고 했는데
이 말은 이렇게 다이어그램을 만들어볼 수 있을 거 같다
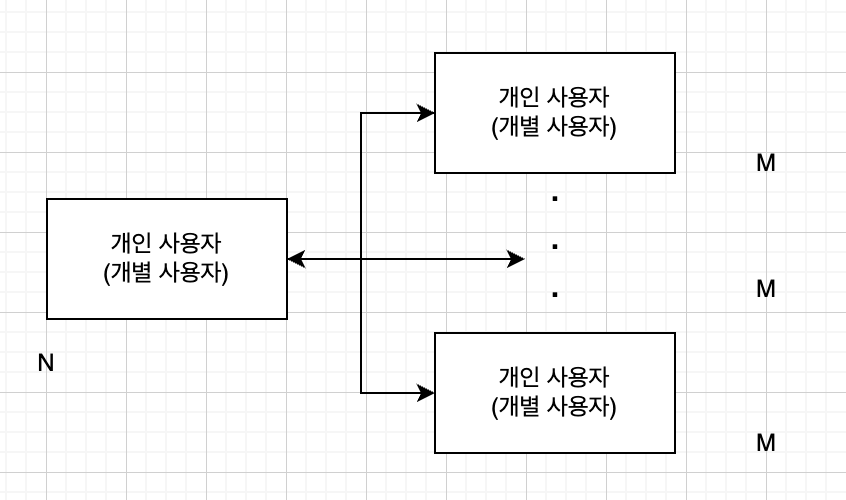
팬아웃을 경험하기 위해서 세마포어로 했고 각 비동기 메서드를 API라고 가정 웹서버의 초당 요청 수를 해보았다
내가 임시로 작성한 코드에서 각각 가칭 API를 사용자가 굉장히 많은 사용을 한다고 가정하고 시작해 보기로 한다
- 나는 이렇게 했다
- 사용자가 로그인하고 → follow 가 구독을 하고 → follow 가 어떤 API를 사용했는지..
- 이렇게 하면 대충 말하는 책에서 말하는 상황과 비슷하게 연출할 수 있을 거 같다... 제발이다 그냥..
예제를 만들어보자
semaphore = asyncio.Semaphore(10) # 동시에 10개의 작업만 허용
async def fetch_toss_data(transaction_id: str) -> Dict[str, str]:
# Simulate fetching Toss transaction data
amount = round(random.uniform(50, 10000), 2)
return {
"transaction_id": transaction_id,
"amount_usd": amount,
"status": random.choice(["Completed", "Pending", "Failed"]),
}
async def fetch_danggeun_data(transaction_id: str) -> Dict[str, str]:
# Simulate fetching Danggeun transaction data
price = round(random.uniform(5, 200), 2)
item = random.choice(["스마트폰", "노트북", "책", "가전제품"])
return {
"price_usd": f"{item} - {price}",
"status": random.choice(["Sold", "Available"]),
}
async def fetch_upbit_data(trade_id: str) -> Dict[str, str]:
# Simulate fetching Upbit trade data
amount = round(random.uniform(0.001, 5.0), 4)
price = round(random.uniform(1000, 50000), 2)
return {"trade_id": trade_id, "amount_btc": amount, "price_usd": price}
async def fetch_hyperconnect_data(stream_id: str) -> Dict[str, str]:
# Simulate fetching Hyperconnect stream data
viewers = random.randint(50, 5000)
return {"stream_id": stream_id, "viewers": viewers}
async def fetch_yahoo_data(stock_symbol: str) -> Dict[str, str]:
# Simulate fetching Yahoo stock data
price = round(random.uniform(50, 1500), 2)
change = round(random.uniform(-5, 5), 2)
return {"stock_symbol": stock_symbol, "price_usd": price, "change_percent": change}
async def insert_data(data: Dict[str, str]):
...
async def fetch_data(
service_name: str,
id: str,
delay: float,
fetch_function: Callable[[str], Dict[str, str]],
) -> Dict[str, str]:
....
async def fanout_simulation() -> None:
services: list[tuple[str, Callable[[str], dict[str, str]], list[str]]] = [
("토스", fetch_toss_data, ["TX001", "TX002", "TX003"]),
("당근", fetch_danggeun_data, ["TRX001", "TRX002", "TRX003"]),
("업비트", fetch_upbit_data, ["TRADE001", "TRADE002", "TRADE003"]),
("하이퍼커넥트", fetch_hyperconnect_data, ["STREAM001", "STREAM002", "STREAM003"]),
("이얏호응", fetch_yahoo_data, ["AAPL", "GOOGL", "TSLA"]),
]
...구현
- 사용자가 자신의 타임라인을 요청하면 팔로우하는 모든 사람을 찾고 이 사람들의 모든 API 사용을 찾아서 시간순으로 정렬해서 합치는 수순으로 해볼 수 있다
select
api_table.*,
users.*
from api_table
join users on api_table.using_id = users.id
join follows on follows.followes_id = users.id
where
follows.followes_id = current_user_id- 각 수신 사용자용 API 사용자 확인처럼 개별사용자의 홈 타임라인 캐시를 유지할 수 있을 것이다 사용자가 API를 사용하면 사용자는 팔로우하는 사람을 모두 찾고 팔로워 각자의 홈타임라인 캐시에 새로운 API 사용을 삽입할 테니 요청 결과를 미리 계산하기에 비용이 저렴할 수 있다
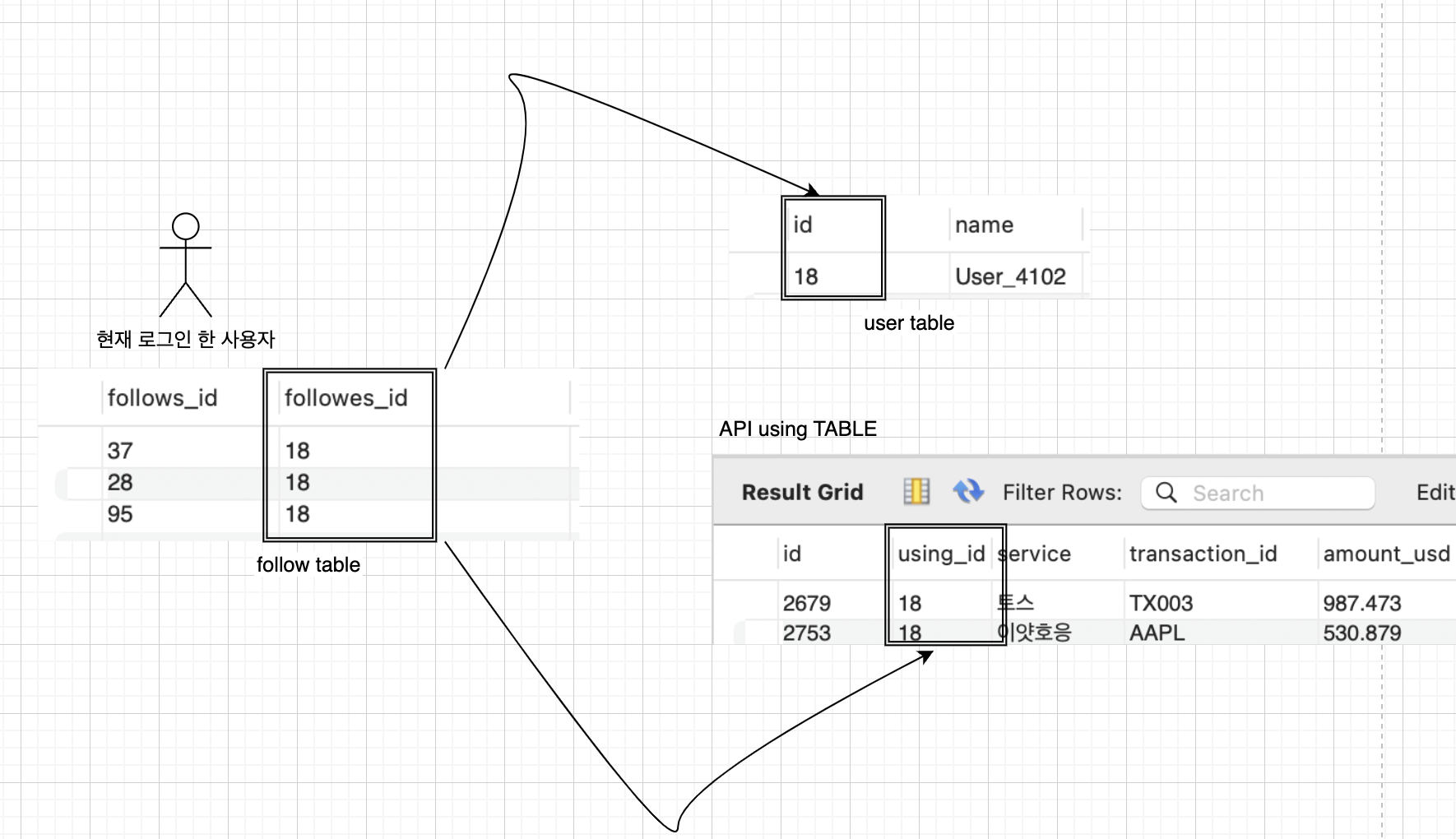
트위터는 첫 번째 버전은 접근방식 1번을 사용했다고 한다
- 이는 시스템이 홈 타임라인의 질의 부하를 버터내기 위해 고군분투 해야 했다고 한다 왜 그런지 살펴보자
- 알아볼 것도 없긴 한데 실시간으로 사람들이 엄청 들어오는데 한번 해보자..
- API 사용량은 꾸준히 증가
- 나의 맥북 M1 수준으로는 초당 3천 건이 계속 생성되었다
- 총데이터는 74만 건
- 나의 맥북 M1 수준으로는 초당 3천 건이 계속 생성되었다
- 사용량 증가, 팔로워 증가 해보겠다..
- 안 해도 될꺼같다..
- API 사용량은 꾸준히 증가
- 알아볼 것도 없긴 한데 실시간으로 사람들이 엄청 들어오는데 한번 해보자..


그러므로 접근 방식 2번으로 했다고 하는데 평균적으로 트윗 게시 요청량이
홈 타임라인 읽기 요청량에 비해 수백 배 적기 때문에 접근 방식 2가 훨씬 잘 동작한다고 한다
쓰기 시점에서 더 많은 일을 하고, 읽기 시점에 적은 일을 하는 것이 바람직하다고 했다
접근 방식 2의 불리한 점은 트윗 작성이 많은 부가 작업을 필요로 한다는 점이라는데
평균적으로 트윗이 약 75명의 팔로워에게 전달되므로
초당 4.6k 트윗은 홈 타임라인 캐시에 초당 345K가 쓰기가 된다고 한다
내가 실습을 위해 만든 것 또한 계산해 보면
- 트윗을 API 호출이라고 생각하고, 팔로워는 해당 API를 호출하는 사용자들이라고 볼 수 있는 것이고
- 즉, 한 명의 API 소유자(사용자)가 API를 호출할 때마다 그 호출이 약 75명의 팔로워들에게 전달되는 것처럼, 한 번의 API 호출이 여러 사용자에게 결과를 전달한다고 할 수 있다
- 초당 4.6k 트윗은 초당 4.6k API 호출을 의미하고,
- 이 호출들이 각각 75명의 사용자(팔로워)에게 전달되므로,
- 초당 345k 호출 결과가 팔로워에게 전달되는 상황이라고 할 수 있다
그러나 평균값은 사용자마다 팔로워 수가 매우 다르다는 사실..
즉, 일부 사용자는 팔로워가 3천만 명이 넘는다 이것은 곧, 단일 트윗이 홈 타임라인에 3천만 건 이상 요청이 될 수 있다는 말인데..
이걸 내가 만든 예제로 한다면…


- 한 명의 사용자가 API를 호출하면 그 호출 결과가 그 사용자의 3천만 명 팔로워에게 전달되는 것..
- 따라서 1회 API 호출은 단일 이벤트가 아니라 3천만 개의 결과가 생성되어 각 팔로워에게 전달되는 것이고..
- 초당 4.6K API가 호출된다면 각 호출이 3천만 명 팔로워에게 전달된다고 가정
- 초당 총 쓰기는 4,600 * 30,000,000 일 것이고
- 138억 번의 캐시 쓰기 작업이 초당 발생하는 것..
- 초당 총 쓰기는 4,600 * 30,000,000 일 것이고
- 초당 4.6K API가 호출된다면 각 호출이 3천만 명 팔로워에게 전달된다고 가정
- 따라서 1회 API 호출은 단일 이벤트가 아니라 3천만 개의 결과가 생성되어 각 팔로워에게 전달되는 것이고..


결국
트위터 사례에서 사용자당 팔로워의 분포(해당 사용자의 트윗 빈도에 따라 편중될 수 있는데)
팬 아웃 부하를 결정하기 위해 확장성을 논의할 때는 핵심 부하 매개변수가 된다
application 마다 다르겠지만 부하에 대한 추론에 비슷한 원리를 적용할 수 있을 것이다..
그래서 트위터는 어떻게?
접근 방식 2가 견고하게 구현돼 트위터는 두 접근 방식의 혼합형으로 바꾸고 있다고 함
대부분 사용자의 트윗은 계속해서 사람들이 작성할 때 홈 타임라인에 펼쳐지지만
- 팔로워 수가 많은 소수 사용자는 팬 아웃에서 제외함
- 사용자가 팔로우한 유명인의 트윗은 별도로 가져와 접근 방식 1처럼 읽는 시점에 사용자의 홈 타임라인에 합친다
이것 또한 내가 임의로 구현한 것으로 말하면 다음과 같다
- 사용자가 API를 만든 사람이 자신의 API를 호출할 수 있는 기능을 제공하고 있고 (만든 사람이 유명인이라고 가정해 보자)
- 팔로워는 그 유명인의 API 결과를 소비하는 사용자들 즉, 유명인이 만든 API의 결과를 사용자들이 API를 호출해서 받아보는 상황
- API 호출 시점에서의 데이터처리
- API 호출을 처리할 때, 일반 사용자는 자신의 타임라인 데이터를 즉시 가져오지만(상대적으로 유명하지 않는 사람인 경우),
- 유명인의 API 결과는 실시간으로 API 호출 시에만 동적으로 가져와서 처리
- 즉, 유명인의 API 결과는 미리 팔로워들에게 자동으로 배포되지 않고,
- 팔로워가 API를 호출하는 시점에만 API 결과를 받아서 타임라인에 동적으로 합쳐지는 방식.
- API 호출을 처리할 때, 일반 사용자는 자신의 타임라인 데이터를 즉시 가져오지만(상대적으로 유명하지 않는 사람인 경우),
결국 미리 대규모로 처리하는 대신, 동적으로 데이터를 결합해서
시스템의 부하를 줄이는 방식으로 비유할 수 있다
성능 기술하기
일단 시스템 부하를 기술하면 부하가 증가할 때 어떤 일이 일어나느지 조사할 수 있음
- 부하 매개변수를 증가시키고 시스템 자원은 변경하지 않고 유지하면 시스템 성능은 어떻게 영향을 받을까?
- 부하 매개변수를 증가시켰을 때 성능이 변하지 않고 유지되길 원한다면 자원을 얼마나 많이 늘려야 할까?
pyspark로 재현해 보았다
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
import time
# Spark 세션 시작
spark = SparkSession.builder.appName("Load Test Example").getOrCreate()
# 데이터 생성 함수
def generate_data(num_rows):
# 데이터프레임 생성
df = spark.range(num_rows).selectExpr("id", "id * 2 as value")
return df
# 데이터 처리 함수
def process_data(df):
# 간단한 데이터 처리: 필터링 및 집계
processed_df = df.filter(col("value") % 2 == 0)
count = processed_df.count()
return count
# 부하 테스트 함수
def load_test(num_rows):
df = generate_data(num_rows)
# 처리 시작 시간 기록
start_time = time.time()
# 데이터 처리
count = process_data(df)
# 처리 종료 시간 기록
end_time = time.time()
# 처리 시간 계산
processing_time = end_time - start_time
print(f"Processed {num_rows} rows in {processing_time:.2f} seconds. Count: {count}")
# 부하 매개변수 테스트
if __name__ == "__main__":
# 예를 들어, 부하를 1백만, 5백만, 1천만 행으로 증가시켜 테스트
for num_rows in [10000000]:
load_test(num_rows)
# Spark 세션 종료
spark.stop()
나의 강력크한 M1 막크북크에서는 천만 개에 3초 정도..
Processed 1000000 rows in 3.55 seconds. Count: 1000000
Processed 10000000 rows in 3.60 seconds. Count: 10000000
Processed 50000000 rows in 3.56 seconds. Count: 50000000

머쓱하다.. 일관되게 처리했다 평균적으로 3.5초 이내.. 너무 데이터셋이 단순해서 그럴 수 있다고 생각한다
하둡과 같은 일괄 처리 시스템은 보통 처리량에 관심을 가진다
온라인 시스템에서 더 중요한 사항은 서비스 응답 시간 즉 클라이언트가 요청을 보내고 받는 것에 시간을 더 중요하게 생각한다
클라이언트가 몇 번이고 반복해서 동일한 요청을 한다고 하더라도 매번 응답 시간이 다르다 실제로 다양한 요청을 다루는 시스템에서 응답
시간은 많이 변한다 응답 시간은 단일 숫자가 아니라 측정 가능한 분포로 생각해야 한다
보통 사용자가 얼마나 오랫동안 기다려야 하는지 알고 싶다면 중앙값이 좋은 지표이다 사용자 요청의 절반은 중앙값 응답 시간 미만으로 제공되고, 나머지 반은 중앙값 보다 오래 걸린다..
특이 값이 얼마나 좋은지 확인하려면 상위 백분위를 살펴보는 것도 좋다 요청의 95%, 99% 99.9%가 특정 기준치보다 더 빠르면 해당 특정 기준치가 각 백분위의 응답 시간 기준치가 됨
95 분위 응답 시간이 1.5초라면 100개의 요청 중 95개는 1.5초 미만이고,
100개 요청 중 5개는 1.5초보다 더 걸린다고 할 수 있다
꼬리 지연 시간으로 일려진 상위 백분위 응답 시간은 서비스의 사용자 경험에 직접 영향을 주기 때문에 중요하다
아마존은 100밀리 초 증가하면 판매량이 1% 줄어들고 1초 느려지면 고객만족도 지표는 16% 떨어지는 현상을 관찰했다고 함...
반면 99.99 분위를 최적화하는 작업에는 비용이 너무 많이 들어서 아마존이 추구하는 목표에 충분히 이익을 가져다주지 못한다고 함
최상위 백분위는 통제할 수 없는 임의 이벤트에 쉽게 영향을 받기 때문에 응답 시간을 줄이기가 매우 어려워 이점은 더욱 줄어듦
말이 좋지 그냥 배보다 배꼽이 커지는 작업은 그냥 내버려 두었다고 하는 거다

부하 대응 접근 방식
부하 수준 1단계에 적합한 아키텍처로는 10배의 부하를 대응할 수 없음
여러 가지 이유가 있겠는데.. 급성장하는 프로세스가 있었다면 자주 바꿔야 할 수 있을 수도 있다
.... 이거는 솔직히 쓸 말이 없어... 요..

유지보수성
다필요 없다 3가지만 있다면 될꺼같다
1. 운용성
- 시스템을 원활하게 운영할 수 있게 쉽게 만들자
2. 단순성
- 시스템 복잡도를 최대한 제거해서 엔지니어가 시스템을 이해하기 쉽게 만들자!
3. 발전성
- 시스템을 쉽게 만들 수 있게 변경할 수 있게 하자
단순성: 복잡도 관리
복잡도 수렁에 빠진 소프트 웨어는 커다란 진흙덩어리라고 말한다
이러한 복잡도를 제거하는 위한 최상의 도구는 추상화이다.. 좋은 추상화는 깔끔하고 직관적인 외관 아래로 ㄹ많은 세부 구현을 숨길 수 있음 또한 좋은 추상화는 다른 다양한 애플리케이션에도 사용 가능하다 이러한 재사용은 비슷한 기능을 여러 번 재구현 하는 것보다 더 효율적
'책 > 데이터 중심 어플리케이션 설계' 카테고리의 다른 글
| 저장소와 검색 (2) (1) | 2024.10.01 |
|---|---|
| 저장소와 검색 (1) (0) | 2024.09.30 |
| 신뢰할 수 있고 확장이 가능하며 유지보수하기 쉬운 어플리케이션 (2) (0) | 2023.04.03 |
| 신뢰할 수 있고 확장이 가능하며 유지보수하기 쉬운 어플리케이션 (1) (0) | 2022.11.10 |



