
스토리가 계속 이어집니다 이전 편을 보고 오시면 더욱 이해가 좋습니다!
https://sky-develop.tistory.com/98
다시 돌아온 코인 프로젝트 (0)
오랜만에 포슽잉 이예요 리프레쉬 이후 다시 씽나게 저의 목적을 향해 다시 글을 써보려고 합니다 완성은 한 상태이고 하나하나 차근차근 복기를 해보며 지나가려고 합니다 거래소 선택
sky-develop.tistory.com
커넥션을 연결하여 저는 각 스키마 마다 다음과 같이 모든 거래소에서 뽑았습니다..!!
| timestamp | 타임스탬프 |
| opening_price | 시가 |
| trade_price | 현재가 |
| high_price | 고가 |
| low_price | 저가 |
| prev_closing_price | 지난 종가 |
| acc_trade_volume_24h | 24시간 평균 볼륨 |
| signed_change_price | 전일 대비 값 |
| signed_change_rate | 전일 대비 등락율 |
설계의 목적과 변경성
처음의 저는 모든 ticker의 원천 데이터 (아무것도 정제되어 있지 않는 데이터) 를 카프카에 송신하여 카프카에 넣고 다시 소비하여 용도에 맞게 전처리를 하는 형식으로 진행을 했습니다 100개씩 모아서 말이죠
카프카의 적재 과정은 다음과 같은 프로세스로 진행하였습니다
- 각 지역별 토픽의 개수는 2개 (ticker 과 orderbook)
- 그 토픽 안에 있는 partition은 지역별 속해져 있는 거래소 개수만큼
- 대한민국 (4개), 아시아(3개), 유럽(2개)
- 여기에서 아쉽다기보단 고려해볼만한 점은 아시아와 유럽을 하나의 토픽으로 합쳐 파티션을 다르게 했었으면 좋았을까 라는 생각이 드는데 복잡성이 그렇게 크지 않고 나중에 확장을 요구했을 때 다시 또 분리해야 할 수 있는 단점이 있어서 이대로 진행하였습니다
- 그러면 각 토픽은 6개 이구 파티션은 모든 토픽 합쳐서 18개 라고 볼 수 있을 거 같아요 만약 이걸 거래소 별로 진행했었으면.. 거래소당 2개 [(9 * 2) * 2 = 36개의 파티션...] 이 필요하여 토픽의 복잡성은 3배를 줄이고 파티션은 2배를 줄여서 자원을 절약할 수 있었습니다..!!
- 대한민국 (4개), 아시아(3개), 유럽(2개)
다시 본론으로 넘어와 서 100개당 크기를 구해본 결과 역시 원천 데이터를 그대로 가지고 오니.. 용량은 당연히 백만 바이트가 넘었었고
저는 생각했습니다.. 본래의 목적은 전처리를 원천쪽에서 많이 진행하면 무거워지는 것이라고 생각하여
수집 로직과 전처리 로직을 따로 구분하여 서로의 모듈의 역할을 고정하고 유지보수성을 높게 가지고 가자라고 생각했습니다
하지만 생각했습니다..
스키마 가 다 필요한게 아닌데.. 왜..? 오히려 더 부하만 가중시키는 거 아닌가?
max_batch_size를 높이면 그만큼 레이턴시가 느는 거 아닌가..?
그리고.. 내가 엄청 많은 컬럼을 뽑는 건가..? 부하가 그렇게 심하지도 않을 텐데?
이거 잘못했다 바꾸자..!!라고 생각하여
전에 1편에서 보여드린 yml에 내가 원하는 스키마를 제작한 뒤 yml 파일을 불러오는 함수를 작성
def ticker_json(location: str) -> list[str]:
"""
JSON 파일 로드 (socket 또는 rest)
- 어떤 가격대를 가지고 올지 파라미터 정의되어 있음
"""
yml_path = f"{path}/config/_marekt_all_ticker.yml"
with open(file=yml_path, mode="r", encoding="utf-8") as file:
market_info = yaml.safe_load(file)
return market_info.get(location.lower(), {}).get("parameter", [])
## websocket_interface
def process_filtered_data(self, filtered_message: ResponseData, ticker_columns: list[str]) -> ResponseData:
"""메시지 데이터를 필터링하여 처리"""
def _process_data(data: dict | list, ticker_columns: list[str]) -> dict:
"""딕셔너리나 리스트 데이터를 처리"""
target_dict = data[0] if isinstance(data, list) else data
return {col: target_dict[col] for col in target_dict.keys() if col in ticker_columns}
message_data = {}
for key, value in filtered_message.items():
if key not in ["data", "result", "time_ms", "ts", "timestamp"]:
if key in ticker_columns:
message_data[key] = filtered_message[key]
continue
match value:
case int() | float() as v:
message_data[key] = v
case dict() | list() as d:
message_data.update(_process_data(d, ticker_columns))
return message_data
웹소켓을 보내는 부분에서 ticket_json과 함께 특정 칼럼을 타고 들어가 요소를 뽑아줘! 전처리 로직을 제작하였습니다..!! 그렇게 하여 생성되는 메시지를 기존에서 10배 이상 줄일 수 있었기에 더욱 더 안정적인 실시간 을 만들 수 있었으며 카프카의 부하를 최대한 줄일 수 있는 목적을 달성하였습니다!! 매치 표현식을 작성해서 가독성을 더 좋게 만들어서 훨씬 더 안정적인 코드를 만들 수 있었습니다..!!
1차 전처리 로 나는 무엇을 추구하였는가?
저는 카프카로 특정 지역의 거래소는 파티션을 적재하여 특정 파티션에는 특정 거래소의 데이터만 들어갈 수 있게 만들었습니다
저는 여기에서 커다란? 트레이드오프에 빠졌었죠
어떤 트레이드오프였니?
- 특정 거래소에 특정 파티션에 데이터가 있으니 컨슈머로 소비를 할 때 집단 consumer group를 만들었을 때.. consumer rebalancing을 사용할 수 없었습니다 그 이유는..
- 특정 파티션의 거래소에 컨슈머 하나를 맞길 바랐습니다 즉 컨슈머 하나당 특정 파티션 하나인 거죠 그러면 다이어그램으로 표현하여 이렇게 지정할 수 있습니다
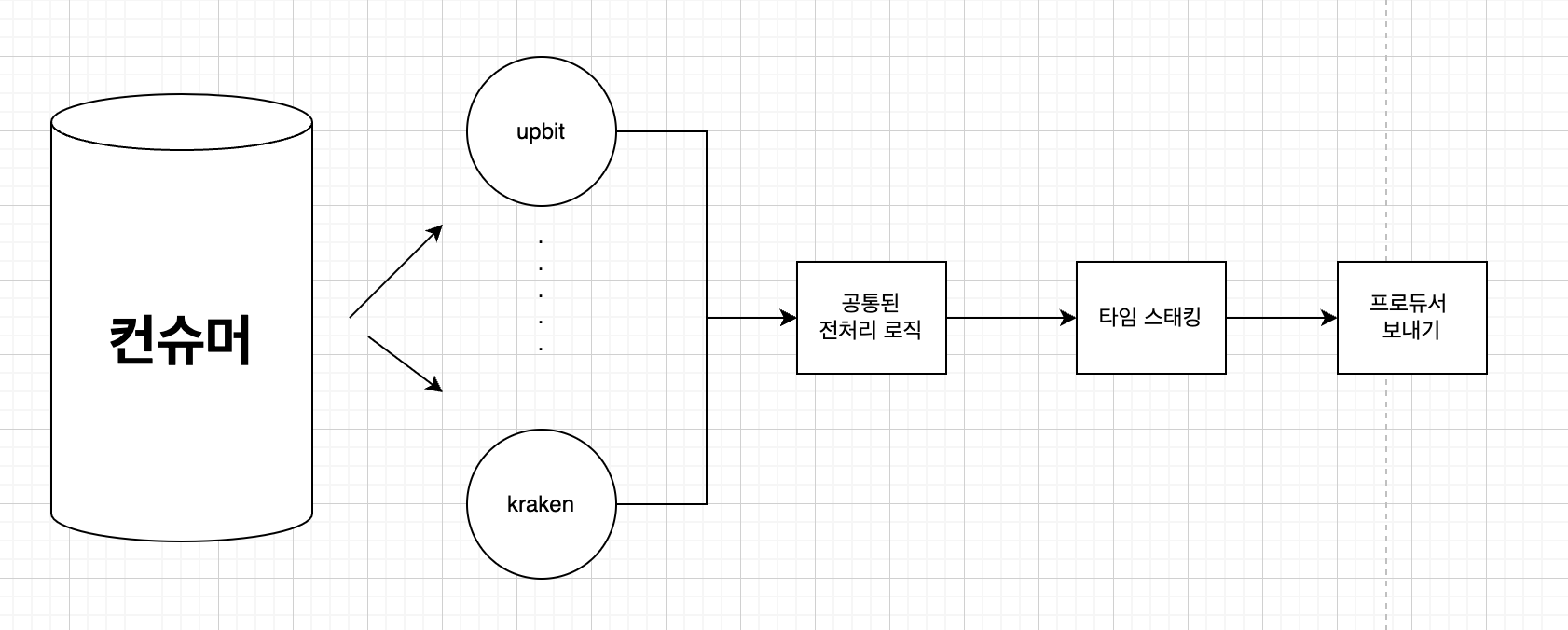
각 거래소마다의 타임스탬프가 있기에 병렬 컨슈머 그룹 집단을 만들고 하나의 파티션당 하나의 컨슈머를 할당했을 때
consumer rebalanceing (이하 CR이라고 지칭하겠습니다)으로 인해서 다른 파티션이 매칭이 되었을 때 전처리 가 되는 것인가?
거래소마다 스키마가 다르기 때문에 절대로 안된다..
를 결론을 맺었습니다

근데 지금 생각해 보면 ticker는 데이터를 전처리 하는 로직은 pydantic으로 공통 로직이 묶여 있기 때문에 충분히 가능할꺼같은 생각이 들어요 하지만 orderbook은 최대한 많은 영수증을 가지고 와야 다채롭게 보여줄 수 있다고 생각하여 각 거래소마다 전처리 로직이 달라 기존 CR를 사용을 할 수 없었습니다 사용한다고 해도 각 거래소 마다 전처리 로직이 다르니 CR로 인하여 재배치를 받아도 전처리가 진행되지 않고 Null 이 리턴됩니다..
그래서 저는 첫 번째로 consumer ID를 하나만 해서 모든 토픽을 소모하도록 해보았습니다 그러면 하나의 컨슈머 ID가 모든 토픽을 감당해야 하니.. 왜 쓰는 거지?라는 의문감과 함께 다시 원점으로 돌아와서..
그러면 결국 수동 파티션 소비하는 assigner를 사용하여 특정 토픽에서 특정 파티션을 소비하도록 수동 지정해야 하죠
관리포인트가 많이 지는 건 사실이었습니다.. 전 선택해야 했습니다 아니죠
정확하게 말하면 전 선택지가 없었습니다 수동 파티션으로 들어갔습니다..

파티션을 모니터링하여 주기적으로 컨슈머가 박살이 나는지 확인해야 하며 다음과 같이 클래스를 만들었습니다
...
class PartitionManager:
"""카프카 파티션 모니터링을 위한 클래스"""
def __init__(
self,
consumer: AIOKafkaConsumer,
topic: str,
assigned_partition: int | None,
) -> None:
...
async def start_monitoring(self) -> None:
"""파티션 모니터링 시작"""
# 모니터링 태스크 시작
self._monitor_task = asyncio.create_task(self._monitor_partitions())
await self.logger.debug(
f"파티션 {self.assigned_partition}에 대한 모니터링이 시작되었습니다.",
)
async def stop_monitoring(self) -> None:
"""파티션 모니터링 중지"""
...
async def _monitor_partitions(self) -> None:
"""파티션 할당 상태 모니터링"""
while True:
current_assignment = self.consumer.assignment()
expected_partition = TopicPartition(self.topic, self.assigned_partition)
# 현재 할당된 파티션이 예상과 다른 경우 경고
if expected_partition not in current_assignment:
await self.logger.warning(
f"""
파티션 할당 불일치 감지:
예상 파티션: {self.assigned_partition}
현재 할당: {[p.partition for p in current_assignment]}
토픽: {self.topic}
컨슈머 ID: {self.consumer._client._client_id}
""",
)
else:
await self.logger.debug(
f"""
파티션 상태 정상:
할당된 파티션: {self.assigned_partition}
토픽: {self.topic}
컨슈머 ID: {self.consumer._client._client_id}
""",
)
await asyncio.sleep(60) # 1분마다 체크주기적으로 파티션 1분마다 체크하여 파티션이 제대로 일치하게 소비되고 있는지를 모니터링하는 클래스를 직접 작성하였습니다
만약 불일치 하거나 is not None 이 되면 다시 수동으로 지정할 수 있도록 작성하였고
timestamp - kafka - DEBUG - 파티션 0에 대한 모니터링이 시작되었습니다.
timestamp - kafka - DEBUG -
파티션 상태 정상:
할당된 파티션: 0
토픽: asiaSocketDataIn-ticker
컨슈머 ID: Asia-client-Ticker-65
timestamp - kafka - DEBUG -
파티션 상태 정상:
할당된 파티션: 0
토픽: neSocketDataIn-orderbook
컨슈머 ID: NE-client-Orderbook-39
timestamp - kafka - DEBUG -
파티션 상태 정상:
할당된 파티션: 2
토픽: koreaSocketDataIn-orderbook
컨슈머 ID: Korea-client-Orderbook-51이렇게 모니터링하여 소비할 수 있도록 진행하였습니다 물론 수동으로 파티션을 조작하는 것이니 consumer 옵션에서 enable_auto_commit 은 False로 진행하였고요
이제 이 클래스를 작성할 수 있도록 configuration 클래스를 만들어줄 필요가 있었습니다 코드로서 설명하기에는 너무 길기 때문에
먼저 3줄 요약을 해보면
- 기본 설정( group_id, producer로 보낼 토픽 이름을 선정)
- ticker와 orderbook마다의 클래스를 만들어 설정 정보를 작성
- 각각 지역과 거래소 파티션 번호를 매핑해주고 각각 거래별 클래스 메타데이터를 생성한다

이렇게 진행하여 각 클래스마다 어떻게 진행해야 하는지에 대한 설정 정보를 담을 수 있었습니다
그러면 이러한 설계로 각 클래스마다 컨슈머를 둔 형태로 진행을 했다라고 보시면 될꺼같아요!
https://github.com/MajorShareholderClub/MarketFirstPreprocessHub/blob/main/mq/kafka_config.py
MarketFirstPreprocessHub/mq/kafka_config.py at main · MajorShareholderClub/MarketFirstPreprocessHub
Contribute to MajorShareholderClub/MarketFirstPreprocessHub development by creating an account on GitHub.
github.com
프로듀서는?
프로듀서도 똑같이 수집 과정과 똑같이 전처리한 데이터의 용량을 보고 결정하였습니다..!!
많이 해준 설정은 없고 용량 또한 그렇게 크지 않았기에 일반 설정으로도 충분했었습니다!!
그래서 어떻게 전송했는데?
컨슈머를 공통적으로 사용할 CommonConsumer 만들었으며 ticker와 orderbook을 추상메서드를 두어 각각 거래소마다
CommonConsumer를 상속받아 전처리 로직을 두었습니다 ticker은 제가 원하는 칼럼을 만들어서 컬럼을 일원화하기 때문에
거래소마다 따로 지정할 필요 없이 위에서 만들었던 카프카 메타데이터와 함께 함께 timestamp 칼럼과 함께 작성하였습니다..!!
class GateIoAsyncTickerProcessor(BaseAsyncTickerProcessor):
def __init__(self, **kafka_meta: dict) -> None:
data = kafka_meta
super().__init__("time_ms", **data)
ticker은 각 거래소 마다 이런식으로 작성되어 있습니다
orderbook은 거래소마다 스키마가 다르기 때문에 부모에서 정의한 추상메서드를 구현함에 있어서 해결하였습니다..!

여기서 자문자답
ticker 하고 orderbook의 consumer를 따로 두는 게 괜찮아 보이는데? 그러면 ticker CR 효과를 받을 수 있으니 부담성이 더 줄지 않을까? 맞습니다.. 관리 포인트는 늘겠지만 충분히 시도해 볼 만한 가치가 충분하다고 생각합니다 근데 딱히 늘 것도 없을 거 같아요 오히려 두 개를 수동파티션을 관리하는 것보다는 훨씬 나은 거 같습니다 한번 시도해 봐야겠어요
사용할 클래스를 같이 dictionary로 묶어 factory 패턴을 만들었으며 기존에 만들었던 config 파일과 같이 클래스와 같이 dictionary에 매핑한 후 클래스 생성자와 카프카 metadata를 주입함에 있어서 실행하였고 최초 1회만 실행하면 되기 때문에
lru_cache를 config를 성하는 사이즈만큼 두어 생성하였습니다..!!
그러므로 자주 호출되는 함수의 결과를 메모리에 저장하여 동일한 입력으로 함수가 호출될 때 저장된 값을 사용하면 되니
훨씬 효율적이다라고 볼 수 있죠! 클래스나 kafka metadata는 변하지 않기 때문에 더 효율적으로 사용할 수 있었습니다..!!
자세하게 보고 싶으면 아래의 URL를 타주세요..!
https://github.com/MajorShareholderClub/MarketFirstPreprocessHub/blob/main/src/config.py
MarketFirstPreprocessHub/src/config.py at main · MajorShareholderClub/MarketFirstPreprocessHub
Contribute to MajorShareholderClub/MarketFirstPreprocessHub development by creating an account on GitHub.
github.com
일일이 계속적으로 데이터를 보내면 카프카에 부하가 너무 심해지는 건 사실이니 특정 시간이나 배치가 쌓였을 때
카프카에 데이터를 전송하도록 진행하였습니다 좀 더 세밀하게 배치를 조정하기 위해서 TimeStacking을 따로 만들었습니다
지금의 설계 구조상

이런 식으로 진행이 되기 때문에 타임 스태킹을 사용하여 특정 배치 또는 시간이 지나면 보내는 형식이 모든 클래스에서 하나를 사용하기 때문에 여러 개의 데이터를 타임 스태킹 모듈이 동시에 처리하고 프로듀서로 전송하려고 할 때, 다음과 같은 동시성 문제가 생길 수 있습니다
데이터를 적재를 할 때 시간 간격 동안 데이터를 수집하다 일정 조건이 맞으면 데이터를 플러시 하여 외부로 전달하게끔 작성하였습니다
여기에서 모든 거래소가 이 타임 스태킹을 거쳐가니 위에서 말하는 동시성 문제가 일어날 수 있다고 가정하는 바 Redis의 분산 락을 사용하여 데이터의 일관성을 보장하였습니다 그러면 분산시스템에서 순서를 보장받을 수 있기 때문에 훨씬 더 효율이 좋은 설계로서 시작될 거니깐요!!
만약 데이터 전송 flush 가 실패할 겨우 DLT에 전송하여 에러와 메시지와 함께 처리 중 오류가 발생해도 데이터를 잃지 않고 안전하게 보관할 수 있게 하여 고가용성을 보장하였습니다!
MarketFirstPreprocessHub/src/common/admin/time_stracker.py at main · MajorShareholderClub/MarketFirstPreprocessHub
Contribute to MajorShareholderClub/MarketFirstPreprocessHub development by creating an account on GitHub.
github.com
이미 프로젝트는 다 끝난 상태입니다 미리 코드를 보고 싶으시면 다음 URL를 타주세요
많은 피드백 질타 부탁드리겠습니다
읽어주셔서 감사합니다..!!

https://github.com/MajorShareholderClub
MajorShareholderClub
MajorShareholderClub has 5 repositories available. Follow their code on GitHub.
github.com
근데 현 프로세스에서 분산락을 적용할 때 스택에 쌓여 있으면 병목이 될 가능성이 있을 텐데...라고 하면
클러스터 도입해야겠죠? 하핳..
특정 예외 로직을 좀 더 세분화할 필요가 있습니다.. 프로젝트의 치명적인 단점인 거 같아요 개선해 보겠습니다..
다음 편에 계속..
'핀테크프로젝트 > 코인' 카테고리의 다른 글
| 새롭게 단장하는 코인 프로젝트.. (3) | 2025.04.13 |
|---|---|
| 다시 돌아온 코인 프로젝트 (2) (0) | 2024.11.17 |
| 다시 돌아온 코인 프로젝트 (0) (1) | 2024.11.09 |
| 거래소별 API 분석 각 거래소 별 캔들 데이터는 무사한가 (0) | 2024.01.29 |
| 코인 모듈 그 첫번째 각 거래소 API 정형화 하기 (1) (0) | 2024.01.29 |



